Blogging at the Death Reference Desk has been interesting, entertaining, befuddling and more. We get the occasional reference question, but it’s mostly pulling in news articles and other content through RSS feeds (the deathwire, as I calls it) and selecting, summarizing and commenting on items of interest.
I do, however, look for opportunities to dig deeper–to be a librarian, not a blogger, and add research value, not regurgitate the web. My recent post, Premature Burial Device Patents, was one such opportunity. As keen to explain the search process as share the information, I fear I may have gotten a tad too library science enthusiastic for the audience. So I figured I’d elaborate more here. In short, gasp! massive, wondrous patent classification system! And Google Patents is a bit broken yet still manages to be reasonably awesome.
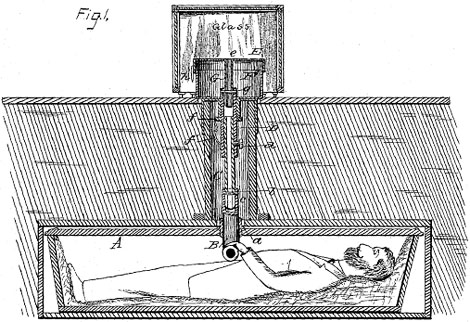
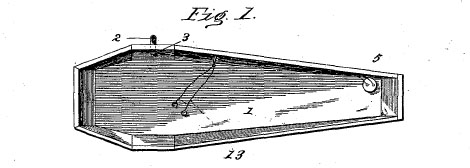
Inspiration struck for this post when one of those skim-friendly web lists came down the deathwire—10 Horrifying Premature Burials. This is not typical DeathRef fodder. It’s ad-laden, the photos are cheesy and the references, scattershot vague. But it did get me thinking—premature burial was a genuine fear, rational or not, around the turn of the twentieth century, and inventors of the time were up to the task. Be that task cheating death and saving lives or exploiting the fear of paranoid Victorians, who knows. But the patents for such devices poured in—plans and designs for spring-loaded escape coffins and electrical systems that detected corpse movement then triggered alarm systems above ground, to name a couple.
As government documents, US patents are in the public domain, and I wondered if they are online. I started with the United States Patent and Trademark Office (USPTO), which, sure enough, provides patents online—full text (and full text searching) starting in 1976 and image-only patents since 1790. I couldn’t get the image plug-in to work, however (arrrrrghgh!) and search is impenetrable. All this data was at my fingertips but I couldn’t quite grasp it.
Wikipedia’s safety coffin article directed me to this marvelous page at USPTO. This was it—everything I wanted, as far as I could tell, in barely human-readable format. The 27/31 intrigued me the most is that what I think it is? sure enough—classification numbers.
Like most classification systems, the United States Patent Classification System is at first glance amazing. I wanted to swan dive into classes, wallow in all its sprawling facets. But I’m sure upon deeper inspection, it’s driven many a patent librarian or poor legal assistant insane. For my domain of interest:
Class 27, Undertaking:
This class includes coffins or caskets and portable coffin-cases for receiving and transporting dead bodies for burial; processes and apparatus for embalming and preserving the bodies of persons after death; and various attachments, accessories, and devices used in connection with the preparation of the bodies or employed at the time of interment at the grave, such as head-rests, corpse-carriers, lowering devices, life-signals, and the like. Subclass 31, Life Signals:
Alarms or signals used in connection with coffins for indicating life in persons supposed to be dead. |
Bingo. Keywords got nothing on a calculated brain putting things in their places. But what to do with this cumbersome interface?
Enter Google Patents (GP). With a search and view structure much like Google Books, GP has mined all of USPTO’s content and delivers it much more digestibly. All those image-only patents I couldn’t get to work are now slick PDFs I can preview in-browser, see as copy-pastable HTML or download as PDFs. Everything is also now full-text searchable (unlike USPTO’s pre-1976 black hole).
Unfortunately, however, that doesn’t make searching for the patents any easier. In the About GP page, it states:
| As with Google Web Search, we rank patent results according to their relevance to a given search query. We use a number of signals to evaluate how relevant each patent is to a user’s query, and we determine our results algorithmically. |
I’m assuming word frequency and fields play a part. For instance, “coffin” mentioned a lot in a patent, especially in important fields, will increase its relevancy ranking. Great. But there’s so much that happens with web search ranking—a critical mass of users, search optimization, incoming and outgoing links, even domain extensions—that simply aren’t a part of a pile of patents, many of which have faulty information (whether an omission on Google’s part or from the start when extracted from USPTO). Fields are transposed, the inventors becoming their inventions. Other fields are left blank. Words are misspelled and other typos abound, likely from bad OCR.
In other words, Google Patents is familiar, clean and comforting, but keyword searching is still crap.

If you know exactly what you’re looking for, you may have better luck but not necessarily. Advanced search allows you to search by patent number, inventor, date and so forth. You can also search by classification, US and international, which initially thrilled me, but my magic numbers 27/31 for life signal devices rounded up only a handful of results, none of them relevant (like the martial arts uniform top or “duck on the rock” kids’ game). Out of curiosity, I tried searching for other classification numbers: some results appeared relevant while others, again, were way off.
I’m stumped. USPTO can easily retrieve patents based on classification—if they’re using the same data, why can’t Google? Searching by patent number also retrieves a lot of irrelevant results in GP. Despite specifying a field search, it still seems to be doing a keyword search. Many patents refer to other similar patents (including their numbers) to explain how this new one compares or deviates, which can be helpful if researching the evolution of an invention or process. But extraneous, completely different items end up in the mix, too, which frustrates and impedes.
Because I couldn’t generate a list of what I wanted in Google Patents, I used the USPTO 27/31 list to grab the patent numbers which I then searched for in GP to compile a list of life signal coffin devices for the DeathRef post. These are linked to the easy-to-view and use (once you find them) GP patents.
As the titles of these patents are often similar or vague, I annotated a few of them with quotes from the patents. This is where the plain text view came in handy—for easy copy and pasting. But what really blew my mind is the clipping feature found in the upper right:

With Clip you can select with a bounding box any part of a PDF then immediately grab the embed code for the image and presumably do whatever you want with it. I threw a handful into the DeathRef post. These patents have marvelous line drawings—I had planned to download PDFs or take manual screenshots, resize as needed, upload them to the blog then link back to the PDFs. The clipping feature did everything automatically and instantly. Wowza!
I don’t know whether Google takes a snapshot of the image and stores it somewhere, or if the code is a script that generates the image on the fly based on the bounding box parameters—I think it’s the latter. While it’s always good practice to have local copies of images in case something happens to ones stored elsewhere (beyond your control), this is a slick feature I haven’t seen before, from Google or anyone else. I suspect it’s the absence of copyright that makes this possible more so than newly discovered technical ingenuity, but still—so handy, so cool.
In conclusion, I love what Google Patents is doing but arughg! it could be so much better. I have a hunch making improvements on providing access to something in theory already available is of pretty low priority, however—and it does say it’s beta, so *deep breath* I can settle down. And in the meantime, be excited. For all the endless ventures and questionable agendas of the Google Empire, this one seems pretty innocuous—and neat.